
The coming revolution in data analysis
- By
- March 17, 2015
- CBR - Economics
We use language to describe, instruct, argue, praise, woo, debate, joke, gossip, relate, compare, reassure, berate, suggest, appease, threaten, discuss, forgive, respond, propose, inspire, complain, interject, boast, agree, soothe, harangue, confess, question, imply, express, verify, interrupt, lecture, admonish, report, direct, explain, persuade.
Every day, we express ourselves in 500 million tweets and 64 billion WhatsApp messages. We perform more than 250 million searches on eBay. On Facebook, 864 million of us log in to post status updates, comment on news stories, and share videos.
Researchers have recognized something in all this text: data. Aided by powerful computers and new statistical methods, they are dissecting newspaper articles, financial analyst reports, economic indicators, and Yelp reviews. They are parsing fragments of language, encountering issues of syntax, tone, and emotion—not to mention emoticons—to discern what we are saying, what we mean when we say it, and what the relationship is between what we say and what we do.
Regina Wittenberg-Moerman, associate professor of accounting at Chicago Booth, finds that debt-analyst reports can provide useful information to bondholders. Wittenberg-Moerman looked at analyst discussions of conflicts of interest between different groups of investors. She and her co-researchers gathered 11,025 sell-side debt-analyst reports on US firms. The find that bondholders should pay close attention to analyst reports that describe an event as good for shareholders and bad for bondholders. Such reports are associated with increases in credit-default-swap spreads.
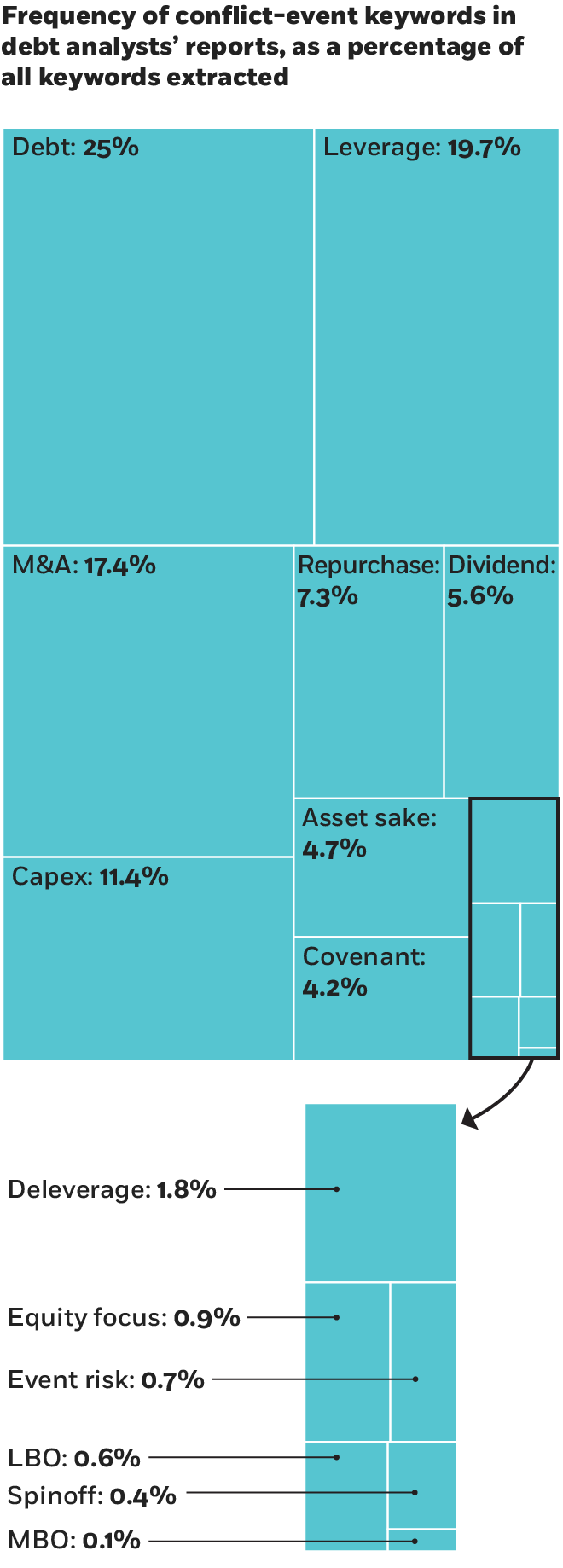
Source: De Franco et al., 2014
They are making new discoveries. Businesses may be able to learn about a product defect before anyone calls customer service. Economists could pinpoint the start of a financial crisis and determine which policy remedies are most effective. Political junkies can use text to understand why the phrase “mashed potato” boded ill for Newt Gingrich’s presidential aspirations—and learn from that, too. Investors can also benefit from analyzing text.
“In econometrics textbooks, data arrives in ‘rectangular’ form, with N observations and K variables, and with K typically a lot smaller than N,” write Liran Einav and Jonathan D. Levin for the National Bureau of Economic Research, in their survey of how economists are using big data. In contrast to those simple textbook models, text data—where observations might be tweets, or phrases from the Congressional Record—are unstructured. They have what researchers call “high dimensionality,” meaning there can be a huge number of variables, and an enormous number of ways to organize them in a form that can be analyzed.
With the advent of cloud computing, the data can be stored on thousands or millions of machines. It’s an engineering feat simply to ensure that all those computers are communicating properly with one another. Einav and Levin suggested in 2013 that economists must begin to study computer-programming languages and machine-learning algorithms if they hope to tackle cutting-edge questions. Two years later, researchers are increasingly doing just that.
One of the pioneers of text analysis is Matthew Gentzkow, Richard O. Ryan Professor of Economics and Neubauer Family Faculty Fellow at Chicago Booth, who first became interested as a graduate student in using text analysis to tease out the economics of the media industry. An important vein of his research seeks to uncover economic reasons behind seemingly ideological choices, such as whether newspapers choose political affiliations to differentiate from their competitors, or whether papers in markets that skew politically liberal or conservative tend to use the words and phrases favored by their readers. Gentzkow’s work won him the 2014 John Bates Clark Medal, given annually to the American economist under age 40 whom a committee of the American Economic Association deems has made the most significant contribution to economic thought and knowledge.
He began developing his ideas about the economics of media—and about the process of text analysis—just as technology was beginning to give researchers far more access to text, through online databases and internet archives that could be analyzed with keyword searches and other methods. “I realized there was a ton of data for this industry that people hadn’t really exploited before,” he says. It wasn’t for lack of trying: as recently as the early 1990s, researchers used a laborious process to transform text into a usable data set. Frequently, graduate students assisting in research projects burrowed through stacks of newspapers and checked off every time a word was used in an article. Their work revealed interesting patterns, but even with this monastic devotion, they could analyze only a small number of newspapers in a year, compared with the number available.
Within a few years, economists had gained access to databases of newspaper articles, as well as scanners that use optical character recognition, which allowed them to digitize hard copies of sources such as, say, newspaper directories dating to the 19th century. Researchers also began to hire people in inexpensive labor markets, including India, to combine optical character recognition with hand searches. The work was still tedious and painstaking—but it was speeding up.
Computers can obviously read text far faster than humans can. But unlike humans, they have to be taught to infer meaning. A researcher trying to teach a machine to do this must provide enough examples, over and over, of how to categorize certain patterns, until the computer can begin to classify the text itself. Think of your email spam filter, which learns from the messages you choose to block. Each time you mark an email as spam, you give the filter a new example that helps it become more accurate.
When Gentzkow and Brown University's Jesse M. Shapiro wanted to measure evidence of media slant in newspapers, they did something similar. To classify newspapers as Republican or Democratic, they started with a body of training text comprising a sample set of articles, and searched for political buzzwords and phrases, such as “death tax” and “undocumented worker,” to see which were widespread.
Gentzkow and Shapiro had originally thought they could train the computer using the political platforms produced by each party. But that didn’t work due to idiosyncratic differences in the platform text that had nothing to do with partisanship. Using the text of presidential debates didn’t work, either. But around the same time Gentzkow and Shapiro were working on this puzzle, Tim Groseclose and Jeffrey Milyo, researchers at UCLA and the University of Missouri, respectively, were searching the Congressional Record to count how many times Republicans and Democrats cited particular think tanks in their congressional speeches, and comparing their counts to how often certain newspapers cited those think tanks.
Influenced by that work, Gentzkow and Shapiro decided to train their computer on the Congressional Record, which captures all the official proceedings and debates of Congress. They wrote computer scripts to scrape all the text from the searchable database. Research assistants, the unsung heroes of text analysis, organized those messy chunks of text in a process Gentzkow compares to painstakingly reconstructing fragments of DNA.
Because the record identifies each speaker, the researchers trained the computer program to recognize the differences in rhetoric between elected Republicans and Democrats. The next step, Gentzkow explains, was to examine the overall news content of a newspaper to determine, “If this newspaper were a speech in Congress, does it look more like a Republican or a Democratic speech?”
To do that, Gentzkow and Shapiro identified how often politically charged phrases occurred in different newspapers in 2005. They constructed an index of media slant and compared it with information about the political preferences of the papers’ readers and the political leanings of their owners. The aim was to find out if the Washington Post, for example, primarily reports the slant preferred by its owner (currently Amazon chief executive Jeff Bezos) or responds to the biases of its customers.
Ultimately, the researchers find that customer demand—measured by circulation data that show the politics of readers in a particular zip code—accounted for a large share of the variation in slant in news coverage, while the preferences of owners accounted for little or none. Gentzkow and Shapiro conclude that newspapers use certain terms because readers prefer them, not because the paper’s owner dictates them.
In another study, Gentzkow, Booth PhD student Nathan Petek, Shapiro, and Wharton’s Michael Sinkinson examined thousands of pages of old newspaper directories—including more than 23,000 pages of text—to determine whether political parties in the late 19th and early 20th centuries influenced the press, measured by the number of newspapers supporting each party, and the newspapers’ size and content.
The era they examine, 1869 to 1928, gives plenty of reason to believe that politicians were manipulating the media for their own advantage. Into the 1920s, half of US daily newspapers were explicitly affiliated with a political party. State officeholders gave printing contracts to loyal newspapers and bailed out failing ones that shared their political agenda.
The researchers note whether each newspaper reported a Republican or Democratic affiliation. They also looked at subscription prices, because papers that were more popular with readers would have been able to charge more. Did Republican newspapers increase in number and circulation when control of a state governorship or either house of the state legislature switched from Democratic to Republican?
In the researchers’ sample, political parties had no significant impact on the political affiliations of the newspapers, with one notable exception: the Reconstruction South. In nearly all of the places where Republicans controlled state government for an extended time, Republican newspapers reached a meaningful share of both daily and weekly circulation while Republicans were in power. Republican shares of weekly circulation rose to 50 percent or more in Arkansas, Florida, and Louisiana while Republicans were in control. But Republicans’ share declined sharply in those states and elsewhere when Democrats regained power.
“Even if market forces discipline government intervention in most times and places, this does not prevent governments from manipulating the press when the market is particularly weak and the political incentives are especially strong,” Gentzkow, Petek, Shapiro, and Sinkinson write.
Another study by Gentzkow and his coauthors, in which they again examine newspapers’ political affiliations and circulation figures, suggests that market competition increases newspapers’ ideological diversity. They also find, separately, that the popular notion of an internet “echo chamber,” where people segregate themselves by ideology, has been overblown. Writing in 2011, Gentzkow and Shapiro assert that most online news consumption is dominated by a small number of websites that express relatively centrist political views. In fact, people segregate themselves according to politics much less online than they do in face-to-face interactions with neighbors or coworkers.
Other researchers are using large-scale text analysis to parse bodies of language ranging from financial statements and company documents to eBay product descriptions to the Google Books corpus, Gentzkow says. “It seems like [text analysis] is going to keep getting bigger as the methodology improves.”

People have been devising increasingly sophisticated ways to analyze text for at least 50 years. In 1963, Frederick Mosteller of Harvard and David L. Wallace of the University of Chicago used a simple form of text analysis to determine the authorship of 12 of the Federalist papers, published anonymously in 1787 and 1788. At the time, historians agreed about who authored most of the 85 papers, but they disputed whether Alexander Hamilton or James Madison wrote these 12 articles.
Working by hand, the researchers counted words in papers known to be written by Hamilton and Madison, comparing rates per thousand for the common words “also,” “an,” and “because.” It was more difficult to use context-rich words such as “war,” because those words depended more on the subject of the paper than on its author. Instead, the researchers looked for these noncontextual words, whose frequency of usage didn’t depend on the topic. They found that Madison used “also” twice as often as Hamilton, while Hamilton used “an” more frequently than Madison.
Mosteller and Wallace created mathematical models to fit their data points and used Bayes’ rule, a theorem for updating the probability of a particular event given additional information. Examining the disputed Federalist papers, they concluded that Madison likely wrote all of them. “We were surprised that in the end, it was the utterly mundane high-frequency words that did the best job,” they wrote.
Today, text analysis is evolving from this relatively simple model to sophisticated regressions involving multiple variables. As the scope of the process expands, researchers and business managers are constructing increasingly lifelike models of communication, with more of the detail and nuance we expect from human conversation.
Some of the complex statistical methods that are driving Gentzkow’s and other researchers’ analyses originate with Matt Taddy, associate professor of econometrics and statistics and Neubauer Family Faculty Fellow at Chicago Booth. At heart, text analysis is still a practice of counting words—or “tokens,” in statisticians’ parlance—and using those counts to make predictions about the speaker or author. Generally, researchers count tokens using what they call a “bag-of-words” approach. Imagine a bag containing all the words in a document or speech, without any context or sentence structure. Someone reaches into the bag and randomly pulls out some words, each of which has a specific probability of appearing in the document. Those probabilities, in turn, are determined by characteristics that are unique to the speaker, such as the person’s political affiliation.
The bag-of-words concept might seem simplistic, but it’s how researchers and businesses learn all kinds of useful variables about the author of a body of text, as Mosteller and Wallace did with the Federalist papers, or Gentzkow and Shapiro did with their analysis of newspapers’ slant. One common application of the bag-of-words approach is to predict sentiment. In its most basic form, this means researchers use word counts of product reviews, for example, to predict whether the authors feel positive, negative, or neutral about the subject of the text.
Taddy, taking sentiment analysis one step further, created a statistical method that dissects a bit of language—it might be a tweet, or a Yelp review, or a congressman’s speech—and combines it with other data to suggest, among other things, the person’s attitude toward the subject. “Typically, people were fairly limited in saying, ‘Was this word occurring when this person was happy or sad?’” Taddy says of earlier models. “Now, let’s take the language and say that it’s a function of not only whether you were happy or sad, but also how much you spend, whom you associate with, what other languages you tend to use.”
Analyzing tweets posted during the 2012 US Republican presidential primaries, Taddy sought to understand how the language used might predict how the tweet’s author felt about a particular candidate. He found that when a word or phrase suddenly took on a different meaning, it signaled something significant about public perception of a candidate.
“The words ‘mashed potato’ had a big negative connotation for Newt Gingrich, and we went into the data to figure out why,” he says. “It turns out that [comedian] Dane Cook had a joke about how Newt Gingrich’s head looked like a mashed potato, and it had gone viral. There were variations on mashed-potato-Newt all over the place, and they tended to be negative.” For business, this could have useful application: there could be money to be made by tracking how language and sentiment changes in fast-moving events.
In his research, Taddy has had to deliberately limit the choices in that random bag of words—by removing very rare words; cutting words to their roots, or “stemming”; removing irrelevant tokens (“if,” “and,” “but,” “who”); converting words to lowercase; and dropping punctuation. But the more he simplifies language, the more he risks removing something meaningful. Emoticons, for example, resemble punctuation, but they convey useful information about the mood of a person writing a tweet or email.
As statistics has evolved to take advantage of increased computing power, Taddy has had to simplify less, and social scientists and business managers can learn more. For example, in the past he might have stemmed the words “taxes” and “taxation” to “tax,” despite their slightly different meanings. Now those distinctions can be captured.
“We learn as much as we can about a simple model, then we start bringing in complexity piece by piece,” Taddy explains.
His approach is helping assess what people buy, what videos they watch, how they will review a product, what groups they belong to, and whom they email. Using sentiment prediction, businesses can uncover problems quickly. Taddy cites a recent example of a company (he can’t disclose the name) that learned through complaints on Twitter that some of its spray cans in one region of the United States were malfunctioning. By analyzing the text of the tweets and the locations of the Twitter users, the business was able to quickly trace the problem to a plug in an injection mold at a single factory.
In a study of restaurant reviews on the now-defunct website We8There, Taddy developed a method to tease out which words were connected with certain attributes of the restaurant. For example, “both ‘dark’ and ‘well lit’ were associated with good ambiance,” he says. “Dim sum, Chinese, and Mexican were associated with value propositions, while steak was highly associated with quality.”
In another study, Taddy used data that Yelp, which publishes business reviews, made available from reviews in the Phoenix area, to predict which reviews the website’s users would find most useful. When a new review comes in, Yelp can use the prediction formula to decide whether to put it at the top of its website.
To train a computer to analyze the reviews, Taddy relied on Yelp’s existing system that allows users to rate reviews as funny, useful, or cool. He analyzed the text of the reviews to predict which ones had useful content, and he found that long-time reviewers tended to be more positive. In instances where two reviews had identical content, the user who had been on the website longer was likely to have given a higher star rating. “One theory is that reviewers who are more into the Yelp community tend to give more positive reviews because they interact with the vendors, they go to Yelp parties, and so on,” Taddy suggests. Their feelings of belonging to the group might influence their ratings.
To an outsider, this blend of computer science and social science can make answering research questions seem as simple as feeding inputs to a computer. But the computer in question still needs a lot of guidance: humans have to choose what questions they want to answer and how to approach them. And some questions—including some large questions in macroeconomics—still need a lot of hands-on work.
For example, is uncertainty about government action hampering economic growth? To find out, Steven J. Davis, William H. Abbott Professor of International Business and Economics at Chicago Booth, Northwestern’s Scott R. Baker, and Stanford’s Nicholas Bloom use online newspaper archives and a phalanx of research assistants to maintain an index of economic policy uncertainty.
To determine whether newspapers cited policy uncertainty more often at certain times, such as when the US Congress was fighting in 2011 about whether to raise the debt ceiling, research assistants read newspaper articles and rated whether they discussed economic policy uncertainty. The researchers compared the human results with automated responses from a computer, and tweaked the computer program accordingly, to increase its accuracy. When the team decided to extend the index back in time to include newspapers dating from 1888, they ran into problems. “The word ‘economy’ didn’t come into modern usage until the 1930s,” Davis points out. “If you read a reference to ‘economy’ in 1910, it would probably be an article on how to run your household or your farm efficiently.” So the researchers created an expanded set of search terms, including “industry,” “commerce,” and “business.”
Davis, Baker, and Bloom have constructed their economic uncertainty index for 11 countries, allowing them to make comparisons—and to raise new questions. For example, the US has shown a significant increase in uncertainty since the 1980s, while the UK has not, even though the two countries have many similarities.
In addition, the researchers are developing a separate project that examines how newspapers explain big daily moves—2.5 percent or more—of stock markets in various countries. Insights from that project could help economists understand what policies cause economies to fluctuate, and why markets seem to move in tandem around the world.
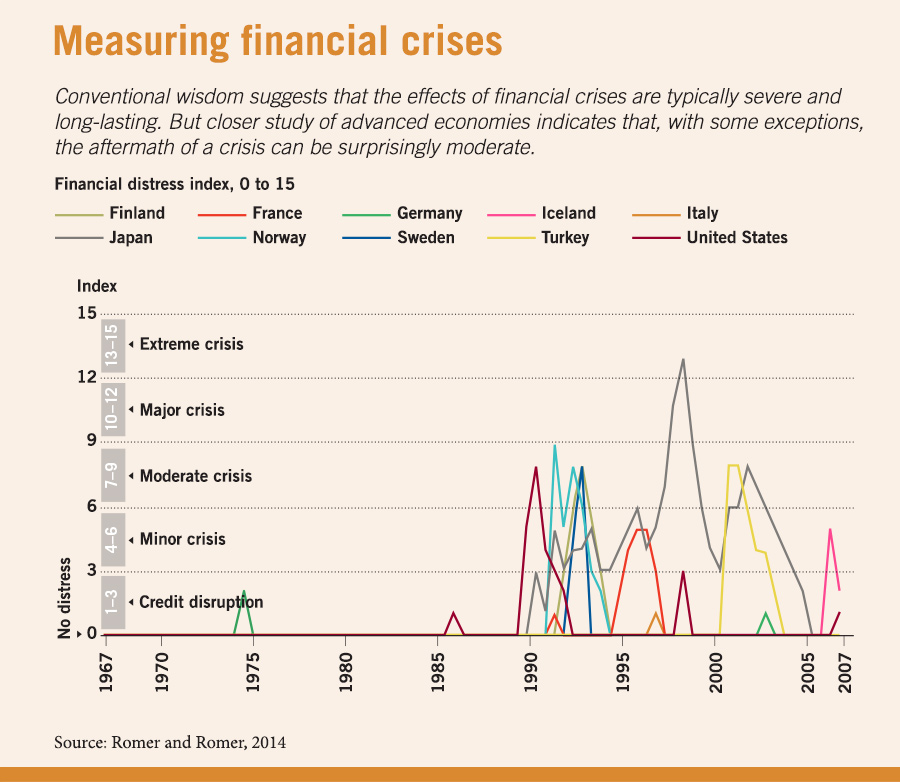
Christina D. Romer and David H. Romer, economics professors at the University of California, Berkeley, also used lower-tech methods of text analysis to study the effects of financial crises. To create a consistent measure of a crisis, the Romers read excerpts from the Organisation for Economic Co-operation and Development’s economic outlook reports, looking for instances when analysts indicated that credit supply was disrupted and financing was becoming harder to secure. From these reports, they also dated the start of financial crises in advanced countries and created a scale to rate the severity of each crisis.
“One of the frustrations I’ve had with the literature [on financial crises] is that it tends to lump together things that may be very different,” says Christina Romer, the former chair of the US Council of Economic Advisers. “A collapse in asset prices can affect the economy, but that’s different from your financial system getting into trouble, and that’s also very different from businesses or households facing bankruptcies.”
The Romers find, contrary to other economists, that aftermaths of financial crises in most advanced economies, with the exception of Japan, have not been that enduring or severe.
If that’s the case, economists need to look more closely at why the most recent global financial crisis was so devastating, producing the worst worldwide recession since World War II, according to the International Monetary Fund. The Romers deliberately excluded this event from the time period they studied, because it was so much larger than other recent economic downturns that it would have skewed the results. But they argue that their findings could suggest lessons for policymakers studying the most recent crisis. If particular responses (such as austerity measures) delayed recovery, politicians might avoid making the same mistakes next time, Christina Romer suggests.
Researchers who use text analysis to address policy questions in macroeconomics, such as the Romers, and Davis, Baker, and Bloom, are following in the tradition of the late Milton Friedman of the University of Chicago and the late Anna J. Schwartz of the National Bureau of Economic Research, who read the diaries of the head of the Federal Reserve and other textual sources to write their 1963 book A Monetary History of the United States. Friedman and Schwartz argued that changes in the money supply have a dramatic effect on the US economy. Their studies of the diaries, a precursor to modern text analysis, helped them understand the reasons the money supply moved, and so separate times when it fell because the economy was weakening from times when it was having an independent effect on the economy.
Economists and other social scientists are overcoming their wariness of words—once seen as too variable, ambiguous, and unwieldy. Having taken irregular bodies of text and turned the contents into quantities that can be sampled and analyzed systematically, they are now looking beyond numbers to find data.
And we are contributing a flood of text to help them better understand human behavior. In the next few years, internet-connected devices such as Amazon’s new Echo, which responds to voice commands in the home, could provide researchers even more language-based data about how people live, work, and spend their money. Powerful computers will process and package those data more quickly and conveniently. Text analysis is beginning to provide insights that would have been impossible to reach a few decades ago. It also creates the space for an entirely new set of questions, which will occupy the next generation of researchers.

An expert panel discusses some of the most important risks and trends facing investors, executives, and policy makers.
What Will Move the Global Economy in 2024?
Princeton sociologist Matthew Desmond discusses the roots of and solutions to poverty in the US.
Capitalisn’t: Why America’s Poor Remain Poor
Ideas abound for a simpler, more effective tax regime.
Is the Tax Code beyond Fixing?Your Privacy
We want to demonstrate our commitment to your privacy. Please review Chicago Booth's privacy notice, which provides information explaining how and why we collect particular information when you visit our website.